For the past two decades, optimizing a website meant structuring content so a search engine would rank it and a human would click it.
The audience is changing.
We are entering the agentic web, where AI systems do not just read your site to answer a question – they navigate it, retrieve from it, and increasingly act on a user’s behalf.
The shift to agentic systems changes what an SEO strategist is actually optimizing for. The metric is no longer just visibility in a results page. It is also whether an agent can read your business, trust what it reads, and execute against it.
Most of the industry is still talking about prompt hacks and pasting llms.txt files at the root of every site.
Meanwhile, the actual infrastructure for the agentic web is being quietly standardized by engineers.
Several pieces shipped recently are worth pulling together: Google’s new Open Knowledge Format, Mark van Berkel’s mapping of the modern data stack, and Myriam Jessier’s argument about brand depth.
Read alongside each other – together with the Lighthouse audit and Gemini’s GBP integration I covered earlier – they describe one architecture from five different angles.
Here is what I am taking from them.
The illusion of the visual web
Most websites are still built exclusively for human eyes. Content management systems like WordPress mix data, design, and logic into a single visual layer. A visual-first design works for human readers.
It works less well for AI agents.
Agents do not look at your design, as I covered in my Agentic Browsing breakdown. They read the DOM and the accessibility tree. If your “Request a Quote” button is a styled <div> with no semantic label, an agent does not know it is a button. It cannot click it. It cannot complete the task on a user’s behalf. And this could mean losing a qualified lead simply because an AI agent couldn’t physically ‘see’ the button to finalize the conversion.
The visual layer is the first hurdle. To matter to an agent, a site has to behave as a machine-readable data layer underneath the visual one.
The ingestion layer: moving from pages to graphs
Mark van Berkel (CTO and co-founder of Schema App) recently published part four of his series on the modern data stack for the agentic web, and his central premise is one every SEO needs to internalize: you cannot prompt your way out of bad data.
In other words, his point is that most brands stop their semantic work at the ingestion layer – pasting JSON-LD Schema markup on a page, validating the syntax, and calling it a day. That is page-level structured data, and it is fragmented by design.
The shift Mark argues for is from isolated pages to a Content Knowledge Graph: an entity layer underneath the website where products, authors, services, and locations exist as persistent objects with explicit relationships, independent of any individual page. That same governed entity layer can simultaneously serve structured data, APIs, AI retrieval systems, and future AI experiences from one source.
He also identifies the layer most teams skip: governance. Validating that JSON-LD is syntactically correct is not the same as validating that it accurately represents the business. Governance asks whether the same entity, product, or service is described consistently across the site, third-party platforms, and the underlying entity layer. Schema drift is what happens when nobody is checking.
This is the technical foundation of what Myriam Jessier calls Brand Depth in her recent Search Engine Land piece, which I broke down separately. Her two-game frame is useful: parametric weight – what a model has internalized about your brand over training – and retrieval survival, what makes it through the model’s pipeline at inference time.
As Myriam puts it: if your messaging is inconsistent, your brand’s vector in the model’s embedding space stays fuzzy. The model is then less likely to surface you when a relevant topic comes up.
Entity coherence stops being an SEO nicety and becomes a baseline trust signal for AI.
Google’s Open Knowledge Format: what it actually is
On June 12, 2026, Google Cloud published the Open Knowledge Format (OKF), authored by Sam McVeety and Amir Hormati (McVeety is Tech Lead for Data Analytics, Hormati is Tech Lead for BigQuery – both inside Google Cloud’s Data Cloud division).
It is worth reading the original post, because most of the early commentary I have seen overreaches on what it covers.
Plainly: OKF v0.1 is an open specification for representing curated knowledge as a directory of markdown files with YAML frontmatter.
The structured fields the spec calls out are minimal – type (the only required field), plus conventions around title, description, resource, tags, and timestamp. Concepts cross-link with normal markdown links, and bundles can include index.md and log.md files for hierarchy and history.
The full v0.1 spec fits on one page.

(Source: Google Cloud, “Introducing the Open Knowledge Format”)
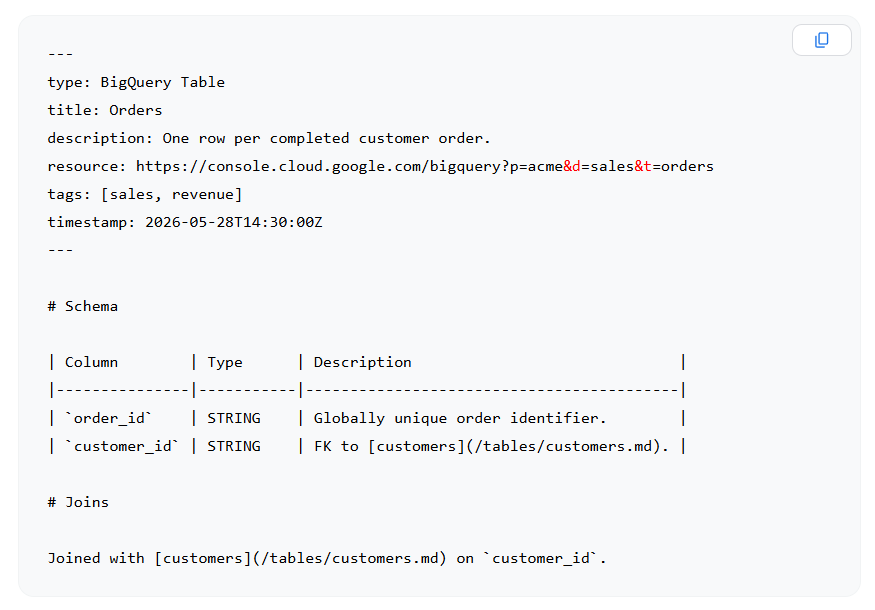
(Source: Google Cloud, “Introducing the Open Knowledge Format”)
No SDK. No proprietary runtime. No vendor lock-in.
The format is the contract.
Two things worth being precise about, because the framing matters:
What Google says OKF is for
Read directly, the Google Cloud post positions OKF as a format for internal organizational knowledge that foundation models need when building agentic systems: the schema of a BigQuery table, the meaning of an internal metric, the runbook for an incident, the join paths between two systems.
The reference implementations Google shipped – an enrichment agent that walks BigQuery datasets, sample bundles for GA4 e-commerce, Stack Overflow, and Bitcoin public datasets – sit squarely inside that internal-knowledge use case.
Google Cloud’s own Knowledge Catalog has been updated to ingest OKF.
Where the broader read comes from
OKF formalizes the same AGENTS.md / CLAUDE.md / Obsidian / LLM-wiki pattern that Andrej Karpathy described in his LLM Wiki gist, and which is already in use across coding agents and developer-tool ecosystems.
Marie Haynes pointed this out the day after the announcement: OKF could plausibly replace Notion or Obsidian for agent-readable knowledge bases more broadly.
So:
OKF is not (yet) being positioned as the way an external AI agent will read your public-facing business. It is a format for the knowledge layer inside an organization, with the explicit invitation from Google for the ecosystem to extend it elsewhere. Watching whether it gets adopted beyond that scope, and by which agent vendors, is the actual signal here.
Still, what it does make tangible – and this is the part I would carry into client conversations – is the direction the industry’s most senior engineers think the knowledge substrate should look like. Markdown plus minimal YAML, in version control, readable by humans and parseable by agents, with no translation layer between them. That is the shape the underlying infrastructure is converging on.
This is also the cleaner reframe for the llms.txt debate I covered last month.
llms.txt is a community convention proposed by Jeremy Howard, useful in one narrow lane (coding agents reading developer documentation), and not currently used at scale beyond that. OKF is a more substantive specification for a similar problem – and it is closer to what the LLM-wiki pattern was always trying to be.
The action layer: becoming “callable”
The architectural piece on top of all of this is the action layer.
In my Agentic Browsing breakdown I covered WebMCP, the proposed standard co-authored by Google and Microsoft that lets a site expose specific actions – a search form, a booking flow, a checkout – as structured tools an agent can call directly.
Mark van Berkel refers to the same idea as Agentic Entry Points: structured service definitions that tell an AI system what your business can do.
WebMCP is still early. The origin trial expands in Chrome 149, the spec is still moving, and most sites that run the Lighthouse audit today will see WebMCP marked Not Applicable. The point is not that this is shippable for every client tomorrow. The point is that when you stack the layers together, the picture is consistent.

(Source: Mark van Berkel, “The Modern Data Stack for the Agentic Web”)
The brands that publish machine-readable Agentic Entry Points become operative. The brands that do not, end up represented by whichever model someone else trained.
Beyond clicks: start building infrastructure
The Google Business Profile update with Gemini, the Lighthouse Agentic Browsing audits, Mark’s modern data stack, Myriam’s brand depth framing, and now Google’s Open Knowledge Format – these are not isolated events.
They are five different vantage points on the same underlying architecture: clean, structured, machine-readable knowledge underneath the visual layer of the web.
What that means for SEO work, practically:
- Treat entity coherence and governance as a baseline. If the same service is described three different ways across the homepage, the location pages, and the footer, you have a brand-depth problem before you have an AI search problem.
- Treat accessibility and layout stability (CLS during interaction, not just on load) as agent-readiness work. That work was already worth doing for humans. It now has a wider audience.
- Watch the format conventions – OKF, AGENTS.md, llms.txt – without rushing to implement any of them on a typical business site today. The agents that would actually read them are mostly not yet operating on commercial sites at scale.
- For sites about to rebuild a checkout, booking, or lead form, understand WebMCP before you scope it. That is the one place the agentic web is concretely close enough that planning for it changes the brief.
The role of an SEO and AI search strategist is narrowing toward what compounds: making sure the data that AI systems read from your business ecosystem is accurate, coherent, and unambiguous enough that whatever the model decides to do with it is worth signing your name to.
The rules of discovery are changing, and it is completely natural if the shift from a visual to an agentic web feels overwhelming right now. You don’t have to navigate that transition alone.
If you want a clear, prioritized roadmap of where your site’s architecture currently stands in that shift – combining traditional SEO with AI search readiness, governance, and agent-readability – those are the audits I run.
operating in a continuous loop of observing, reasoning, and executing actions.
