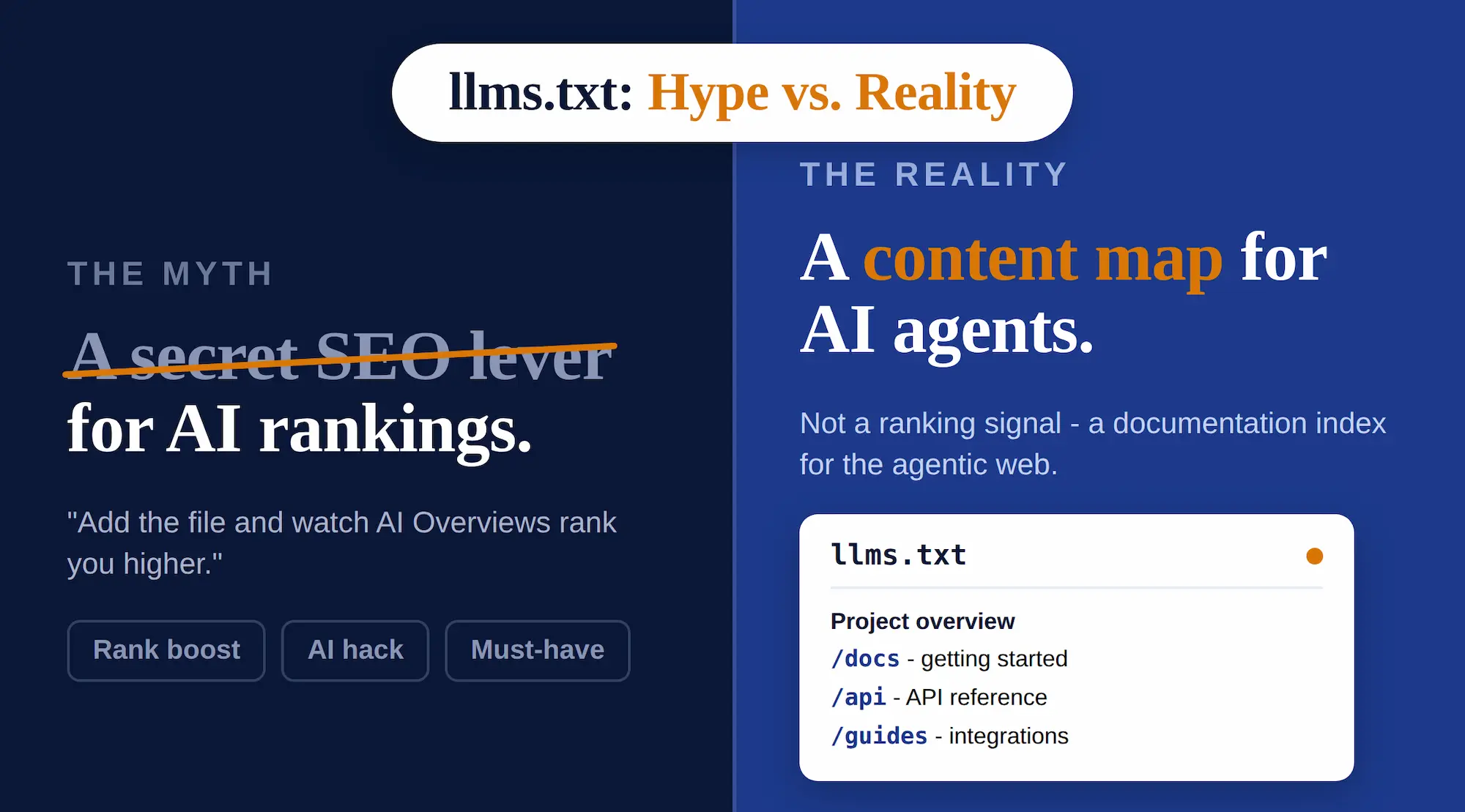
For weeks now, the llms.txt file has been everywhere again. Some sell it as a secret lever for AI search; others declare it useless. Let’s look at what’s actually verifiable.
What llms.txt file is
The llms.txt file is placed at the root of your site (yoursite.com/llms.txt). Think of it as the table of contents at the front of a book: a short description of what the site is about, then a curated list of its most important pages. The idea is that an AI model shouldn’t have to crawl your entire cluttered HTML just to understand where everything lives.
It helps to separate three terms that are similar enough to get mixed up:
- robots.txt is a traffic sign – it tells bots which parts of the site they may and may not enter. It’s been around for decades, and today it’s exactly how you control AI crawlers too.
- llms.txt is a content map for AI – a list of links, not the content itself.
- markdown pages are stripped-down, clean versions of individual pages (no design, no ads). The llms.txt file usually links to them.
Where the idea came from
The llms.txt file was proposed by Jeremy Howard, co-founder of Answer.AI and a well-known figure from fast.ai, on September 3, 2024. No major AI player invented it. The problem he set out to solve is real: model context windows are limited, and when an AI tries to read documentation across a pile of HTML pages full of menus and scripts, tokens get spent on formatting instead of content.
Important: to this day it’s a community convention, with no backing from any official standards body and no enforcement mechanism. “Standard” is too strong a word.
What Google says about llms.txt
On May 15, 2026, Google Search Central published its official guide for optimizing for generative AI. In the “mythbusting” section, it states plainly: you don’t need llms.txt to show up in AI search. A crawler can find it like any other text file, but it gets no special treatment.
A few days later, the Chrome team added a new “Agentic Browsing” category to Lighthouse that checks, among other things, for the presence of llms.txt. It looks like a contradiction – but it isn’t. The Search team is talking about ranking and AI search. The Chrome team is talking about how ready a site is for AI agents that carry out tasks. Two different domains. And importantly: Chrome checks for it without penalty – if you don’t have the file, it’s marked “not applicable,” not an error.
John Mueller made the same point in response to Lily Ray: it’s worth separating discovery (search) from functionality (once an AI agent is already on the page, how it gets the task done). The llms.txt file isn’t from the discovery world.
One note: all of this is Google’s official position. And Google is no longer the only player – there’s OpenAI, Perplexity, Anthropic and other AI systems, none of which have the same public stance on llms.txt. In other words, “Google says no for search” doesn’t automatically mean “the entire AI world says no.” In fact, some readings suggest there’s a more nuanced case for llms.txt with Claude or smaller AI surfaces – just not for Google’s AI search.
Does AI actually read the llms.txt file? The data.
This is the part worth pausing on before you believe anyone who confidently asserts one of the extreme positions.
OtterlyAI ran a 90-day experiment tracking server logs. The result: out of 62,100 total AI bot visits, only 84 requests went to the llms.txt file. That’s 0.1%. The file’s presence didn’t trigger any increase in bot activity, nor did it change crawl patterns.
SE Ranking analyzed roughly 300,000 domains to check whether llms.txt correlates with more frequent AI citations. The finding: no statistically significant correlation. In fact, when they removed llms.txt from their predictive model, accuracy improved – the file was adding noise, not signal.
And Mueller himself said no AI service has confirmed it uses llms.txt, and that you can see it in server logs because they don’t even check for it.
All of this can sound damning – but only if you expect llms.txt to have an effect today. The agentic web is just getting started, so low usage is expected, not disqualifying.
So why does llms.txt file exist – and who uses it
llms.txt file is used by roughly 10% of domains, mostly technical companies with documentation: Anthropic, Stripe, Cursor, Cloudflare, Vercel, and Mintlify.
That’s no accident. The one context where llms.txt currently does measurable work is helping AI tools find their way around technical documentation.
Here’s concretely what that looks like: when a developer works in a tool like Claude Code or Cursor and asks for, say, an integration with some service, the AI tool needs to read that service’s documentation on their behalf. Instead of crawling the whole site blindly, the tool pulls the llms.txt – the documentation map – and finds the right page faster. The “reader” is the AI tool, and the developer gets the benefit (a faster, more accurate result). That’s exactly why sites whose audience is developers (Stripe, Anthropic, Vercel) have llms.txt.
But mind the nuance: those tools use it because the site itself points them to it, not because agents go looking for llms.txt on every site they visit. There’s no public evidence for the latter. There’s even a counter-finding: in one LangChain experiment, a raw llms.txt could confuse the model with excess context and make the result worse.
How to make one (if you decide to)
If you’re building a dev or docs site and want to try:
- Create a markdown file at the root: yoursite.com/llms.txt.
- Structure per the spec (llmstxt.org): project title, short summary, then sections with curated links and a one-line description each.
- You can also point to its location in robots.txt, similar to a sitemap.
- Be careful with markdown copies of pages: if they’re indexable, they introduce duplicate content at scale, which can dilute crawl budget and push down your original pages.
The llms.txt file – is it worth it?
The llms.txt file is not a secret SEO lever – that’s been proven false, and Google has officially confirmed it for its own search. But it’s neither dead nor completely useless. It’s real in one narrow case: technical documentation for developers’ AI tools, today.
For an ordinary business site – e-commerce, services, local business – there’s currently no evidence that llms.txt brings anything. And let’s not forget: Google is no longer the only player; how other AI systems (OpenAI, Perplexity, Anthropic) behave remains to be seen.
My advice: don’t fall for either “it’s mandatory for the future” or “it’s completely useless.” Assess what your site is and who its readers are. It’s not necessary right now, if you’re thinking short-term. And it’s not a bad idea to make one, since it’s not much work, if you’re thinking long-term.
In short: it’s not essential for SEO/AI search right now, but it is a reasonable early preparation – for the agentic web.
_________________________________________________________________________________________
I take on clients for SEO & AI Search readiness consultations.
If you’re not sure whether files like llms.txt deserve a spot on your roadmap – or where your site actually stands as search shifts toward AI – contact me.
Let’s separate what moves the needle today from what’s worth preparing for, and build a plan around your site and your readers.
_________________________________________________________________________________________
